
严格来说,TCP/IP 协定家族并没有定义 “TCP/IP 专属的” 网路硬体规格。硬体的范围实在太过广泛了﹐标准非常多﹐当今大部份的低层网路硬体标准都是由 IEEE 制定的,但也有许多标准是厂商专属的。要让 TCP/IP 协定能够顺利与不同类型的硬体进行沟通﹐那么就需要建立起一些标准协定来让大家共同参考。以我们最常用的乙太网(Ethernet)为例﹐我们无需理会厂商如何设计网路界面的驱动程式﹐一旦它能够被系统接纳﹐网路储存层(Datalink)就能使用网路界面在实体网路上传送和接收资料了。
IP 位址和实体位址对应之困扰
在「网路基础」课程中﹐我们知道乙太网上面使用的传送方式叫 CSMA/CD (Carrier-Sensing Multiple Access with Collision Detection)﹕虽然讯框会在整个网段(segment)中用广播的方式传递﹐而且所有节点都会收到讯框﹐然而﹐只有目的位址符合自己实体位址的讯框才会被接收下来。因此,不管上层协定是哪一种(可以是 TCP/IP 也可以是其它),在底层的传送若是使用 Ethernet 的话,就得使用 MAC (Media Access Control) 实体位址。若要查询到当前系统目前所有界面的实体位址,我们可在 Linux 系统里面输入 ifconfig 命令:
eth0 Link encap:Ethernet HWaddr 00:A0:0C:11:EA:11
inet addr:203.30.35.134 Bcast:203.30.35.159 Mask:255.255.255.224
UP BROADcast RUNNING MULTIcast MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
Interrupt:3 Base address:0x300eth1
Link encap:Ethernet HWaddr 00:80:C7:47:8C:9A
inet addr:192.168.0.17 Bcast:192.168.0.255 Mask:255.255.255.0
UP BROADcast RUNNING MULTIcast MTU:1500 Metric:1
RX packets:12303 errors:0 dropped:0 overruns:0 frame:0
TX packets:12694 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
Interrupt:10 Base address:0x2e0
从上面的命令结果中可发现:关于每一个界面的第一行资讯﹐最后的部份就是该界面的实体位址。讯框在实体网路上面传送的过程中﹐IP 位址(或曰罗辑位址)一点都派不上用场。但问题是:当我们使用 TCP/IP 的时侯,上层的协定都是以 IP 位址为传送依据的。那么﹐这时候我们就必须有一套方法来对应 IP 位址和实体位址了。
在此一过程中﹐关键点是如果将 IP 位址对与实体位址做对应。有些使用简单实体位址的网路(如 proNET-10 )﹐其实体位址只占一个 byte 的长度﹐而且允许使用者在配置网路卡的是选择自己的实体位址。在这样的网路上进行 IP 位址和实体位址的对应﹐是比较简单的﹐我们可以把实体位址设为和 IP 位址设为一样。例如﹐假设某一个节点的 IP 位址为 192.168.1.17﹐那么我们可以将该实体位址设为 17。 这样﹐在 proNET 就可以轻易的根据 IP 位址来得到实体位址。这样的对应非常简单﹐而且要维护起来也很容易﹐在新机器假如网路的时候﹐并不需要修改或重编已存的资料。
然而﹐我们知道在乙太网上﹐每一个实体界面都有一个 48bit(6byte) 的 MAC 位址﹐而 IP (v4)使用的位址则为 32bit(4byte)﹔每各位址格式都只提供相应的层级协定使用﹐彼此是不能互换使用的。这时候我们就无法用简单的数学关系来做 IP 位址和实体位址的对应了。
IP 位址和实体位址的对应方法
建立表格
首先﹐我们想到的最简单方法是在每一台机器上建立一个 IP 位址和实体位址的对应表格( table )。不过这个方法还是没办法解决如下的情形:
· 网路上的节点数量多如恒河沙数﹐要想将全部节点的对应关系列入表格之中几近不可能任务。
· 如果某一个节点产生异动情形(例如更换网卡)﹐那么如果让所有表格正确做出相应修改﹐也是个头痛的问题。
· 对某无磁碟工作站来说﹐因为没有本机的储存设备﹐将无非建立表格。
写入高阶程式
除了建立表格﹐我们还可以将实际的网路位址写死在高阶网路程式里面。不过﹐和前一个方法一样﹐如果遇到硬体位址变更等异动动情形﹐那么﹐程式也需要重新编译过才行。
显然﹐上述两个方法都不怎么高明。
ARP 协定
这里我们要介绍的是 Address Resolution Protocol (ARP)。 ARP 是 TCP/IP 设计者利用乙太网的广播性质﹐设计出来的位址解释协定。它的主要特性和优点是它的位址对应关系是动态的﹐它以查询的方式来获得 IP 位址和实体位址的对应。它的工作原理非常简单:
1. 首先﹐每一台主机都会在 ARP 快取缓冲区 (ARP Cache)中建立一个 ARP 表格﹐用来记录 IP 位址和实体位址的对应关系。这个 Table 的每一笔资料会根据自身的存活时间递减而最终消失﹐以确保资料的真实性。
2. 当发送主机有一个封包要传送给目的主机的时候﹐并且获得目的主机的 IP 位址﹔那发送主机会先检查自己的 ARP 表格中有没有该 IP 位址的实体位址对应。如果有﹐就直接使用此位址来传送框包﹔如果没有﹐则向网路发出一个 ARP Request 广播封包﹐查询目的主机的实体位址。这个封包会包含发送端的 IP 位址和实体位址资料。
3. 这时﹐网路上所有的主机都会收到这个广播封包﹐会检查封包的 IP 栏位是否和自己的 IP 位址一致。如果不是则忽略﹔如果是则会先将发送端的实体位址和 IP 资料更新到自己的 ARP 表格去﹐如果已经有该 IP 的对应﹐则用新资料覆盖原来的﹔然后再回应一个 ARP Reply 封包给对方﹐告知发送主机关于自己的实体位址;
4. 当发送端接到 ARP Reply 之后﹐也会更新自己的 ARP 表格﹔然后就可以用此纪录进行传送了。
5. 如果发送端没有得到 ARP Reply ﹐则宣告查询失败。
ARP 的查询过程可参考下图:
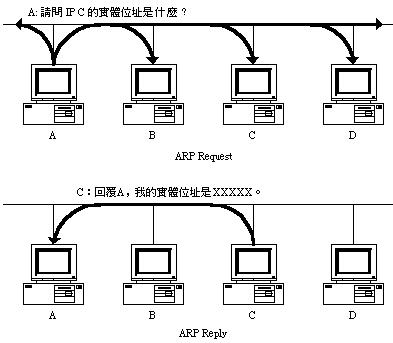
ARP 的查询过程
前面说的 ARP 表格﹐只有在 TCP/IP 协定被载入核心之后才会建立﹐如果 TCP/IP 协定被卸载或关闭机器﹐那么表格就会被清空﹔到下次协定载入或开机的时候再重新建立﹐而同时会向网路发出一个 A广播﹐告诉其它机器它的目前位址是什么﹐以便所有机器都能保持最正确的资料。
然而﹐ARP cache 的大小是有所限制的﹐如果超过了界限﹐那么越长时间没被使用过渡资料就必须清理掉﹐以腾出空间来储存更新的资料。所以﹐当机器收到 ARP equest 封包时﹐如果查询对象不是自己﹐则不会根据发送端位址资料来更新自己的 ARP 表格﹐而是完全忽略该封包。同时﹐每笔存在 cache 中的资料﹐都不是永久保存的﹕每笔资料再更新的时候﹐都会被赋予一个存活倒数计时值﹐如果在倒数时间到达的时候﹐该资料就会被清掉。然而﹐如果该资料在倒数时间到达之前被使用过﹐则计时值会被重新赋予。
当然了﹐ARP 尚有一套机制来处理当 ARP 表格资料不符合实际位址资料的状况(例如﹐在当前连线尚未结束前﹐收到目的端的位址资料更新讯息)﹔或是目的主机太忙碌而未能回答 ARP 请求等状况。
RARP 协定
刚才介绍的 ARP 协定是透过向网路查询而找出实体位址﹐那我们接下来探讨的 RARP 协定则相反﹕它是籍由查询网路上其它主机而得到自己的 IP 位址。
通常﹐我们使用的乙太网卡﹐在出厂的时候就有生产厂家把网卡的实体位址烧在 ROM 里面﹐这个位址是不能改变的(某些型号的网路卡﹐或是透过其它技术手段﹐是允许您修改实体位址的)。不管系统是否起来﹐这个位址都会存在﹐而且要让系统获得它也很容易。然而,在一些无磁碟(diskless)工作站上面﹐系统档案都存放在远端的伺服器﹐当它在启动的时候﹐因为本身没有 IP 位址﹐也就无法和伺服器沟通﹐更不能将系统档案载入。那么﹐我们就必须要有一个办法﹐让这样的无磁碟工作站在和伺服器沟通之前获得自己的 IP 位址。RAPR 协定就是为解决此问题而设计出来的。
和 ARP 协定一样﹐RARP 也是用广播的形式来进行查询﹐只不过这时候问的 IP 位址不是别人﹐而是自己的 IP 位址而已。我们可以从下图看出 RARP 的运作﹐其实和 ARP 是极其相似的:
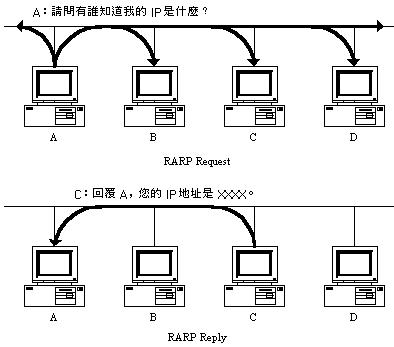
RARP 的查询过程
首先是查询主机向网路送出一个 RARP Request 广播封包﹐向别的主机查询自己的 IP。在时候﹐网路上的 RARP 伺服器就会将发送端的 IP 位址用 RARP Reply 封包回应给查询者。这样查询主机就获得自己的 IP 位址了。
然而不像 ARP﹐查询主机将 RARP Request 封包丢出去之后﹐可能得到的 RARP Reply 会不止一个 (在 ARP 查询中﹐我们可以确定只会获得一个回应而已)。因为网路上可能存在不止一台 RARP 伺服器(基于备份和分担考量﹐极有可能如此设计)﹐那么﹐所有收到 RARP 请求的伺服器都会尝试向查询主机作出 RARP Reply 回应。如果这样的话﹐网路上将充斥这种 RARP 回应﹐做成额外的负荷。这时候﹐我们有两种方法来解决RARP 的回应问题。
第一种方法﹐为每一个做 RARP 请求的主机分配一主伺服器﹐正常来说﹐只有主伺服器才回做出 RARP 回应﹐其它主机只是记录下接收到 RARP 请求的时间而已。假如主伺服器不能顺利作出回应﹐那么查询主机在等待逾时再次用广播方式发送 RARP 请求﹐其它非主伺服器假如在接到第一个请求后很短时间内再收到相同请求的话﹐才会作出回应动作。
第二种方法也很类似﹕正常来说﹐主伺服器当收到 RARP 请求之后﹐会直接作出回应﹔为避免所有非主伺服器同时传回 RARP 回应﹐每台非主伺服器都会随机等待一段时间再作出回应。如果主伺服器未能作出回应的话﹐查询主机会延迟一段时间才会进行第二次请求﹐以确保这段时间内获得非主伺服器的回应。当然﹐设计者可以精心的设计延迟时间至一个合理的间隔。
PROXY ARP
代理 (Proxy) ARP 通常用来在路由器上代为回答。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
“命名数据网络”来了 TCP/IP会退休吗?(下)
面对当今的互联网需求,TCP/IP有些不堪重负,研究人员想要用新的互联网协议栈取代它,这个新协议被称为“命名数据网络(Named Data Networking)”。
-
“命名数据网络”来了 TCP/IP会退休吗?(上)
面对当今的互联网需求,TCP/IP有些不堪重负,研究人员想要用新的互联网协议栈取代它,这个新协议被称为“命名数据网络(Named Data Networking)”。
-
详解TCP/IP协议栈面临的五大网络安全问题(二)
在本文中,笔者重点解析了TCP/IP协议栈面临的五大网络安全问题,也介绍到企业网络安全管理人员在面临问题时所能采取的应对措施。
-
详解网络故障诊断概念以及应用步骤
网络故障诊断作为一门综合性技术,它涉及网络技术的很多方面。在学习网络故障诊断的概念前我们先来看看和其息息相关的网络和路由器的基本概念是什么?